My Favorite Database Technologies
My experiences over the last few years have made Cassandra, Elasticsearch, Snowflake, Spark and others my favorites. Learn more about the technologies that will continue to grow in 2021.


What is Modern Data Technology? A modern data technology lets you bring together all your data at any scale easily, and to get insights through analytical dashboards, operational reports, or advanced analytics for all your users.
Data must be ready and able to keep up with new regulations, changing customer expectations, restructuring or acquisitions. Good data helps you mitigate risk and gain a competitive edge, whereas bad data has the opposite effect. Data empowers any organization to make informed decisions and provides crucial insights into market behaviors and trends. The benefits of properly accessing and analyzing your data are well-known and business-critical.
Driving Data Projects
- Identify Business Objectives and Create Business Value. Meet with key business stakeholders to understand their pain points and the business KPIs that are lagging or suffering from a lack of proper data
- Program alignment with the unique business value drivers of your organization
- Gather Intelligence and Input from Stakeholders. Gaining insight into the data-related pain points of various executives will help you to have a holistic understanding.
- Create Detailed Roadmap
- Present Your Business Case that includes key business use cases, qualitative findings and quotes from your stakeholder interviews. Data driven approach helps quantify the proposed business value. Finally, create an executive summary that ties all of the pieces together, paints a picture of how your program will solve problems and create new opportunities for your organization.
Implement a Modern Data Architecture
Implementing the latest in data technology - stream processing, analytics or data lakes, we often found the data architecture was becoming bogged down with large amounts of data that legacy programs were not able to properly utilize. Evaluate quickly and deploy new technologies in order to keep up with the pace of modern data innovations. Learn from your failures and agile practice of “test-and-learn”, develop a minimum viable product that can be tested to determine value before implementation. Also, invest in DataOps and build a positive data culture.
There are five foundational shifts that my organization took to enable rapid deployment of new capabilities and simplify existing architectural approaches.
-
Shift to Cloud-Based Platforms - Serverless Data Platforms, Containerized Data Solutions
-
Move From Batch to Real-Time Processing - Messaging Platforms and Streaming Analytics Solutions
-
Messaging Platforms – modern messaging platforms provide scalable and fault-tolerant publish/subscribe services that can process and store millions of messages every second. This allows for real-time support and bypasses existing batch-based solutions, resulting in lower costs and a lighter footprint than legacy messaging queues.
-
Streaming Analytics Solutions – these systems allow for direct analysis of messages in real-time and compares historical data to current messages to establish trends and generate predictions and recommendations.
-
Real-time streaming functions allow data consumers to subscribe to “topics” so they receive a constant feed of transactions relevant to their needs. This is commonly stored in a data lake that retains all the granular details for in-depth analysis and forecasting.
-
-
Highly modular data architectures
-
API-based Interfaces – when implemented in your data pipeline, these interfaces shield different, independent teams from the complexity of layers not related to them, which speeds the time to market and reduces the chance of human error. They also allow for easier component replacement as requirements change.
-
Analytics Workbenches – these services enable end-to-end communication between modular components, such as databases and services
-
-
Decoupled Data Access
-
API Gateway – this allows you to create and publish data-centric API’s, empowering you to control access, implement usage policies, and measure performance.
-
Data Buffer – many organizations find it necessary to have a data platform that buffers transactions outside of your core system. This could be a data lake, warehouse, or other data storage architecture that exists for each team’s expected workloads.
-
-
Domain-Based Data Architecture
-
Data Infrastructure-as-a-Platform – these services provide common tools and capabilities for storage and management and empower data producers to implement their data requirements quickly without the hassle of building their own platform.
-
Data Cataloging Tools – these tools allow for the search and exploration of data without requiring full access. The data catalog also typically provides metadata definitions and a simplified interface to access data assets from anywhere.
-
Build vs Buy Decisions
Few questions to answer to initiate the process:
- Cost of buy vs build. What are up-front costs?
- Availability of desired features in the solution that you’re buying
- Extensibility of the solution that you’re buying
- Solution available vs resources available
- Migration pains vs Long-term vision
- Customer service — SLA and Pricing
- Community or forum
- Knowledge documentation
- Are there enough plugins available if you want add more custom features to your solution?
- What are long-term costs (especially the hidden ones like staff time, morale, and opportunity cost)?
- How much would the purchased solution match our specific needs?
- How much extra stuff does the purchased solution have that we don't need, and may get in our way?
- Will we learn anything important by building something we would otherwise buy?
- Will the chosen solution be relatively isolated, or will this decision influence many others down the road?
- How easily can we replace the solution if it turns out we chose wrong?
- To what extent will our needs change over time, and how much flexibility does each approach give us?
- Are we talking about something related to the core value proposition, or something peripheral?
- Can we take some temporary, stopgap action and delay the decision until we better understand our needs?
- Is it your core competency? If not and you’re going to take away from developing the unique capabilities that you offer AND there are third party solutions that exist then you need to consider them.
- How often will it need to be updated? Is the feature or capability something you can build once and never touch (as if that ever happens). If it’s going to need constant updating - further taking time away from core product development - is it worth it?
- How much does it cost? A pretty basic one. Some companies simply prefer to build because it’s perceived to be less expensive because it’s existing salary and opportunity cost. However, determining lost productivity is important - especially in the hyper competitive software market (if that’s what you are in).
Considerations while chosing the Data Technology
- Platform Use Cases
- Integration with Cloud Providers
- Availability & Geolocation of the data
- Volume of data
- Dedicated engineering resources for the support and maintenance
- Scalability: Horizontally vs. Vertically
- Security
- Pricing models
- Performance
- Data Migration
My Top 12 favorite technologies that will continue to lead in 2021
The future of big data is clear and unshakeable. Technologies like IoT, Data Lakes, Edge Computing, Im-memory databases, NoSQL Databases, Machine Learning, artificial intelligence, and more are all using Big Data. A simple example of the Internet of Things is your smart television that is connected to your home network and generating data on your viewing patterns, interests, and more.
Cassandra
🔗 Read more about Cassandra here
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra's support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
Favorite feature
Zero Copy Streaming
Cassandra 4.0 has added support for streaming entire SSTables when possible for faster Streaming using ZeroCopy APIs. If enabled, Cassandra will use ZeroCopy for eligible SSTables significantly speeding up transfers and increasing throughput. A zero-copy path avoids bringing data into user-space on both sending and receiving side. Any streaming related operations will notice corresponding improvement.
Benefits of Zero Copy Streaming
When enabled, it permits Cassandra to zero-copy stream entire eligible SSTables between nodes, including every component. This speeds up the network transfer significantly subject to throttling specified by stream_throughput_outbound_megabits_per_sec.
Enabling this will reduce the GC pressure on sending and receiving node. While this feature tries to keep the disks balanced, it cannot guarantee it. This feature will be automatically disabled if internode encryption is enabled. Currently this can be used with Leveled Compaction.
Snowflake
🔗 Read more about Snowflake here
Snowflake is an analytic data warehouse was built from the ground up for the cloud to optimize loading, processing and query performance for very large volumes of data. Snowflake is a single, integrated platform delivered as-a-service. It features storage, compute, and global services layers that are physically separated but logically integrated. Data workloads scale independently from one another, making it an ideal platform for data warehousing, data lakes, data engineering, data science, modern data sharing, and developing data applications. Snowflake is a "Managed Service", architected specifically for a seamless cross-cloud experience, Snowflake automates data warehouse administration and maintenance.
🔗 Read more about Snowflake here
Favorite feature
Automating Continuous Data Loading
Using Cloud Messaging. Automated data loads leverage event notifications for cloud storage to inform Snowpipe of the arrival of new data files to load. Snowpipe copies the files into a queue, from which they are loaded into the target table in a continuous, serverless fashion based on parameters defined in a specified pipe object.
We leverage auto-ingest with Snowpipe for several of our data pipeline workloads. For example, we were able to automatically ingest data and capture changes from AWS Kinesis through Firehose to S3 and to our Snowflake table without setting up manual “COPY INTO,” and the data is available in almost real time. The cost performance is satisfying as we are able to cut down our pipeline cost by as much as 20 times.
Key Features
- Automatic query caching, planning, parsing, and optimization
- Automatic updates with no scheduled downtime
- Cross-cloud data replication for seamless, global data access
- Connect to the Data Cloud to share and acquire shared data with potentially thousands of Snowflake customers and partners
- Batch and Continuous Data Pipelines for Various Data Formats
- Modern data-driven applications can’t wait for data. Snowflake handles both batch and continuous data ingestion of structured and semi-structured data.
- Native support for semi-structured data with no need to define schema
- Automated and managed data ingestion in near-real time from cloud blob storage with Snowpipe
- Simplify change data capture (CDC) with Streams & Tasks
- Simply load data and run with instant data availability
- Native support for semi-structured data
- Eliminate the need to preprocess semi-structured data. Deliver fresh insights faster with Snowflake’s VARIANT data type.
- Ingest JSON directly into a relational table for immediate insights.
- Use standard SQL to query structured and semi-structured data.
- Avoid breaking data pipelines when adding new features or parameters.
Elasticsearch
🔗 Read more about Elasticsearch here
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements.
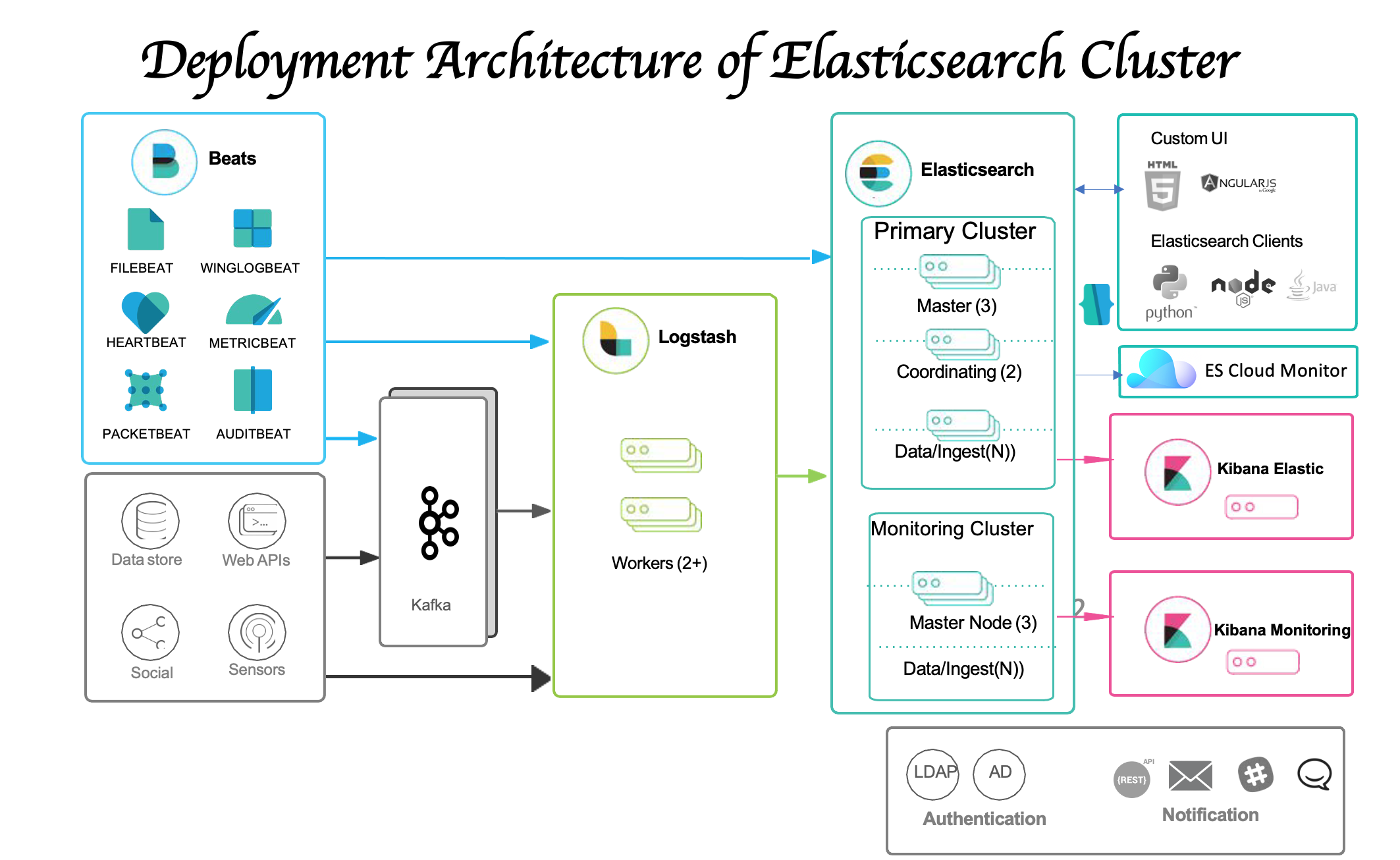
Amazon Redshift
AWS Redshift is an enterprise-level, petabyte scale, fully managed data warehousing service. With Redshift, we can query petabytes of structured and semi-structured data across their data warehouse and data lake with standard SQL. Redshift allows users to save the results of their queries back to the S3 data lake adopting open formats, like Apache Parquet, to additionally analyze from other analytics services like Amazon EMR, Amazon Athena, and Amazon SageMaker. Redshift allows multiple integrations with different technologies, especially with tools on the AWS platform. Unlike Snowflake, Redshift considers that user data is in AWS S3 already for performing tasks. AQUA is a new distributed and hardware-accelerated cache that supports Redshift to go up to 10x faster than any other cloud data warehouse.
Amazon Dynamodb
Amazon DynamoDB is a fully managed proprietary NoSQL database service that supports key-value and document data structures and is offered by Amazon.com as part of the Amazon Web Services portfolio. DynamoDB exposes a similar data model to and derives its name from Dynamo, but has a different underlying implementation.
Key Features
-
DynamoDB uses hashing and B-trees to manage data. Upon entry, data is first distributed into different partitions by hashing on the partition key. Each partition can store up to 10GB of data and handle by default 1,000 write capacity units (WCU) and 3,000 read capacity units (RCU).
-
It's an OLAP database. You'd typically run a star schema on it. It has extremely slow writes, but extremely fast reads even over terabytes of data. and business intelligence (BI) applications, which require complex queries against large datasets.
-
High Availability and Durability - All of your data is stored on solid-state disks (SSDs) and is automatically replicated across multiple Availability Zones in an AWS Region, providing built-in high availability and data durability. You can use global tables to keep DynamoDB tables in sync across AWS Regions.
-
DynamoDB as an integrated AWS service makes it easier to develop end to end solutions. DynamoDB uses tables, items and attributes, MongoDB uses JSON-like documents. DynamoDB supports limited data types and smaller item sizes; MongoDB supports more data types and has fewer size restrictions.
-
Amazon DynamoDB supports PartiQL, a SQL-compatible query language, to select, insert, update, and delete data in Amazon DynamoDB. Using PartiQL, you can easily interact with DynamoDB tables and run ad hoc queries using the AWS Management Console, AWS Command Line Interface, and DynamoDB APIs for PartiQL.
PartiQL operations provide the same availability, latency, and performance as the other DynamoDB data plane operations.
INSERT INTO TypesTable value {'primarykey':'1',
'NumberType':1,
'MapType' : {'entryname1': 'value', 'entryname2': 4},
'ListType': [1,'stringval'],
'NumberSetType':<<1,34,32,4.5>>,
'StringSetType':<<'stringval','stringval2'>>
}
- Amazon DynamoDB transactions simplify the developer experience of making coordinated, all-or-nothing changes to multiple items both within and across tables. Transactions provide atomicity, consistency, isolation, and durability (ACID) in DynamoDB, helping you to maintain data correctness in your applications. Amazon DynamoDB is designed for scale and performance. In most cases, the DynamoDB response times can be measured in single-digit milliseconds. However, there are certain use cases that require response times in microseconds. For these use cases, DynamoDB Accelerator (DAX) delivers fast response times for accessing eventually consistent data.
DAX DynamoDB-compatible caching service
-
DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications. DAX addresses three core scenarios:
-
As an in-memory cache, DAX reduces the response times of eventually consistent read workloads by an order of magnitude from single-digit milliseconds to microseconds.
-
DAX reduces operational and application complexity by providing a managed service that is API-compatible with DynamoDB. Therefore, it requires only minimal functional changes to use with an existing application.
-
For read-heavy or bursty workloads, DAX provides increased throughput and potential operational cost savings by reducing the need to overprovision read capacity units. This is especially beneficial for applications that require repeated reads for individual keys.
In particular, it is important to understand three fundamental properties of your application's access patterns before you begin:
Data size: Knowing how much data will be stored and requested at one time will help determine the most effective way to partition the data.
Data shape: Instead of reshaping data when a query is processed (as an RDBMS system does), a NoSQL database organizes data so that its shape in the database corresponds with what will be queried. This is a key factor in increasing speed and scalability.
Data velocity: DynamoDB scales by increasing the number of physical partitions that are available to process queries, and by efficiently distributing data across those partitions. Knowing in advance what the peak query loads might help determine how to partition data to best use I/O capacity.
Amazon Aurora
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud, that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open source databases.
Amazon Aurora allows you to encrypt your databases using keys you manage through AWS Key Management Service (KMS). On a database instance running with Amazon Aurora encryption, data stored at rest in the underlying storage is encrypted, as are its automated backups, snapshots, and replicas in the same cluster.
Spark
🔗 Read more about Spark here
Apache Spark™ is a unified analytics engine for large-scale data processing at high speed and run workloads 100x faster. Apache Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
We can write spark applications quickly in Java, Scala, Python, R, and SQL. Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
With Spark Read JSON files with automatic schema inference and Combine SQL, streaming, and do complex analytics. Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
Presto
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses while scaling to the size of organizations like Facebook.Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto's new features:
-
Project Presto Unlimited – Introduced exchange materialization to create temporary in-memory bucketed tables to use significantly less memory.
-
User Defined Functions – Support for dynamic SQL functions is now available in experimental mode.
-
Apache Pinot and Druid Connectors
-
RaptorX – Disaggregates the storage from compute for low latency to provide a unified, cheap, fast, and scalable solution to OLAP and interactive use cases.
-
Presto-on-Spark Runs Presto code as a library within Spark executor.
-
Disaggregated Coordinator (a.k.a. Fireball) – Scale out the coordinator horizontally and revamp the RPC stack. Beta in Q4 2020. Isues
Druid
Druid is designed for workflows where fast ad-hoc analytics, instant data visibility, or supporting high concurrency is important. As such, Druid is often used to power UIs where an interactive, consistent user experience is desired. Druid streams data from message buses such as Kafka, and Amazon Kinesis, and batch load files from data lakes such as HDFS, and Amazon S3. Druid supports most popular file formats for structured and semi-structured data.
Kafka
🔗 Read more about Kafka here
Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one end-point to another. Kafka is suitable for both offline and online message consumption. A messaging system sends messages between processes, applications, and servers. Apache Kafka is a software where topics can be defined (think of a topic as a category), applications can add, process and reprocess records. Kafka is a message bus optimized for high-ingress data streams and replay. Kafka can be seen as a durable message broker where applications can process and re-process streamed data on disk."

Here are a few of the popular use cases for Apache Kafka:
-
Messaging
-
Website Activity Tracking
-
Metrics
-
Log Aggregation
-
Stream Processing
-
Event Sourcing
-
Commit Log
Kafka has its own storage but will it replace the need to have a database or can Kafka be used as database? Follow my 🔗 Blog on Kafka to learn more about this
Airflow
Apache Airflow is an open-source Python-based workflow automation tool used for setting up and maintaining data pipelines. An important thing to remember here is that Airflow isn't an ETL tool. Instead, it helps you manage, structure, and organize your ETL pipelines using Directed Acyclic Graphs (DAGs)

Data Cataloging Tools - Amazon Glue
AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams. AWS Glue consists of a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible scheduler that handles dependency resolution, job monitoring, and retries. AWS Glue is serverless, so there’s no infrastructure to set up or manage.
AWS Glue simplifies many tasks when you are building a data warehouse or data lake. It discovers and catalogs metadata about your data stores into a central catalog. You can process semi-structured data, such as clickstream or process logs. It also populates the AWS Glue Data Catalog with table definitions from scheduled crawler programs. Crawlers call classifier logic to infer the schema, format, and data types of your data. This metadata is stored as tables in the AWS Glue Data Catalog and used in the authoring process of your ETL jobs.
Use Cases
-
You can use AWS Glue when you run serverless queries against your Amazon S3 data lake. AWS Glue can catalog your Amazon Simple Storage Service (Amazon S3) data, making it available for querying with Amazon Athena and Amazon Redshift Spectrum. With crawlers, your metadata stays in sync with the underlying data. Athena and Redshift Spectrum can directly query your Amazon S3 data lake using the AWS Glue Data Catalog. With AWS Glue, you access and analyze data through one unified interface without loading it into multiple data silos.
-
You can create event-driven ETL pipelines with AWS Glue. You can run your ETL jobs as soon as new data becomes available in Amazon S3 by invoking your AWS Glue ETL jobs from an AWS Lambda function. You can also register this new dataset in the AWS Glue Data Catalog as part of your ETL jobs.
-
You can use AWS Glue to understand your data assets. You can store your data using various AWS services and still maintain a unified view of your data using the AWS Glue Data Catalog. View the Data Catalog to quickly search and discover the datasets that you own, and maintain the relevant metadata in one central repository. The Data Catalog also serves as a drop-in replacement for your external Apache Hive Metastore.
Further Reading
🔗 Read more about Snowflake here
🔗 Read more about Cassandra here
🔗 Read more about Elasticsearch here
🔗 Read more about Kafka here
🔗 Read more about Spark here
🔗 Read more about Data Lakes Part 1here
🔗 Read more about Data Lakes Part 2here
🔗 Read more about Data Lakes Part 3here
🔗 Read more about Data Lakes Part 4here
🔗 Read more about Redshift vs Snowflake here
🔗 Read more about Best Practices on Database Design here
About the author
Nidhi Vichare is an enterprise AI and data executive, platform architect, and author of The Meaning Layer. She writes about enterprise AI strategy, data architecture, causal measurement, AI ROI, agentic systems, and modern leadership for senior data and AI leaders.